
پس از آمادهسازی داده، نوبت به الگوریتمهای یادگیری ماشین رسید. براساس انواع یادگیری ماشین الگوریتمها در سه دسته بانظارت، بدوننظارت و یادگیری تقویتی قرار گرفتند. توضیح الگوریتمها را با روشهای بانظارت آغاز کردیم. در مقاله رگرسیون چیست با دو روش رگرسیون خطی و رگرسیون منطقی آشنا شدیم. در این قسمت، ماشین بردار پشتیبان را بررسی میکنیم. ماشین بردار پشتیبان از الگوریتمهای مهم یادگیری بانظارت میباشد.
. . . .
ماشین بردار پشتیبان
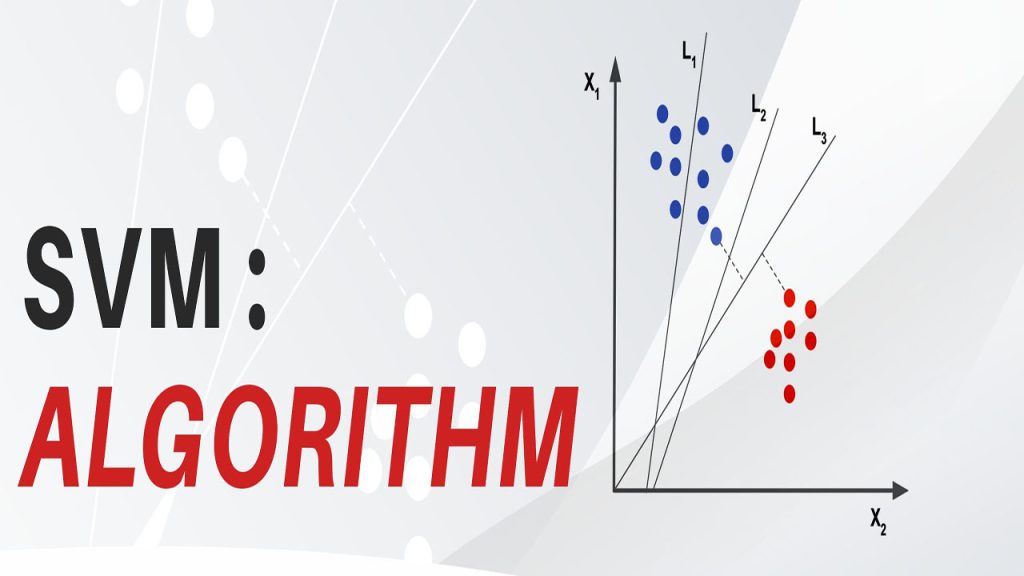
ماشین بردار پشتیبان (SVM: Support Vector Machine)، یک نوع پیشرفته از رگرسیون است که شبیه به رگرسیون منطقی ولی شرایط آن سختگیرانهتر است. در این راستا، ماشین بردار پشتیبان در رسم خطوط مرزی دستهبندی بهتر عمل میکند. شکل زیر رگرسیون منطقی را با ماشین بردار پشتیبان مقایسه میکند.
 به زبان ساده 1")
نمودار پراکندگی در شکل بالا شامل نقاط دادهای است که خطی جداپذیر (Linearly Separable) هستند و ابرصفحه منطقی (A) نقاط داده را به دودسته تقسیم میکند بهطوری که فاصله بین تمام نقاط داده و ابرصفحه حداقل شود. خط دوم، ابر صفحه SVM (B)، دو خوشه را از یکدیگر جدا میکند، ولی از محلی که فاصله بین خودش و دو خوشه حداکثر باشد.
همچنین یک ناحیه خاکستری وجود دارد که حاشیه (Margin) را نشان میدهد – فاصله دو برابر شده بین ابرصفحه و نزدیکترین دادهها. برخی نقاط داده جدید، ابر صفحه رگرسیون منطقی را نقض کرده و نادرست دستهبندی میشوند، برای جلوگیری از چنین مشکلی، ماشین بردار پشتیبان از حاشیه استفاده میکند. برای توضیح این سناریو، همان نمودار پراکندگی را با اضافهکردن یک نقطه داده جدید در نظر میگیریم.
دوره آموزشی: برای ورود به دنیای پروژههای یادگیری ماشین، دوره آموزش یادگیری ماشین به زبان ساده با پایتون را در کانال یوتیوب دیتاهاب ببینید.
 به زبان ساده 2")
در شکل بالا یک نقطه داده جدید به نمودار پراکندگی اضافه شده است. نقطه داده جدید یک دایره است، ولی بهاشتباه در سمت چپ ابر صفحه رگرسیون منطقی (ساخته شده برای ستارهها) قرار گرفته است. بااینحال، نقطه داده جدید، بهدرستی در سمت راست ابر صفحه ماشین بردار پشتیبان (ساخته شده برای دایرهها) باقی میماند، به علت پشتیبانی (Support) وسیعی که توسط حاشیه تولید شده است.
یکی دیگر از کاربردهای مفید SVM کاهش و تعدیل اثر نقاط ناهنجاری (Anomaly) است. یک محدودیت رگرسیون منطقی استاندارد این است که در مواجه با ناهنجاریها از مسیر اصلی خود خارج شده و با آنها سازگار میشود (همانطور که در شکل زیر در نمودار پراکندگی با ستاره در سمت راست پایین دیده میشود). بااینحال، SVM نسبت به چنین نقاطی، حساسیت کمتری دارد و تأثیر آنها را بر روی محل نهایی خط مرز، حداقل میکند. در شکل زیر، میبینیم که خط B (ابر صفحه SVM) نسبت به ستاره ناهنجار در قسمت سمت راست، کمتر حساس است. SVM روش خوبی برای تعدیل اثر نقاط ناهنجاری است.
 به زبان ساده 3")
مثالهای دیده شده تاکنون، از دو ویژگی رسم شده بر روی یک نمودار پراکندگی دوبعدی تشکیل شده است. بااینحال، قدرت اصلی SVM در کار با دادههای با بُعد بالا و سازماندهی ویژگیهای متنوع است. SVM انواع مختلفی برای دستهبندی دادههای با بُعد بالا دارد که بهعنوان “هستهها (Kernels)” شناخته میشوند از جمله SVC خطی (Linear) (که در شکل زیر دیده میشود)، SVC چندجملهای (Polynomial) و ترفند هسته (Kernel Trick). ترفند هسته یک راهحل پیشرفته برای نگاشت دادهها از یک فضای با بُعد کم به یک فضا با بُعد بالاتر است. گذار (Transitioning) از یک فضای دوبعدی به یک فضای سهبعدی این امکان را میدهد تا از یک صفحه خطی برای جداکردن داده در یک فضای سهبعدی استفاده بشود، همانطور که در شکل زیر دیده میشود.
 به زبان ساده 4")
. . . .
و در انتها…
تحلیل رگرسیون روشهای مختلفی داشت که دو روش رگرسیون خطی و رگرسیون منطقی را توضیح دادیم. الگوریتم ماشین بردار پشتیبان نوع پیشرفتهای از رگرسیون بود که در رسم خطوط مرزی بین دستهها عملکرد بهتری دارد. همانطور که در این مقاله گفته شد، ماشین بردار پشتیبان برای دادههایی با بعد بالا بسیار مناسب بود و روشهای مختلفی شامل خطی، چندجملهای، ترفند هسته داشت. صحبت درباره روشهای تحلیل رگرسیون در اینجا تمام میشود. در مقاله بعد، خوشه بندی و روشهای آن بررسی میشوند.
دوره آموزشی: سایتها دادههای زیادی دارند که میتوانید با وب اسکرپینگ آنها را استخراج کرده و دیتاست یادگیری ماشین خود را بسازید. برای این کار دوره آموزش رایگان وب اسکرپینگ را در کانال یوتیوب دیتاهاب ببینید.