
در مقاله یادگیری ماشین به زبان ساده درباره مدل داده و تقسیم مجموعهداده به داده آموزشی و آزمایشی صحبت کردیم. گفتیم برای ساخت مدل داده به الگوریتمها نیاز داریم. ولی مشکل این است که الگوریتمهای یادگیری ماشین زیادی وجود دارند که هر کدام ویژگی ها و کاربرد خود را دارند. از کجا بفهمیم کدام الگوریتم مناسب است و باید از آن استفاده کنیم؟ در این قسمت انواع یادگیری ماشین را توضیح میدهیم تا بدانیم برای هر مسئلهای کدام الگوریتم مناسب است.
. . . .
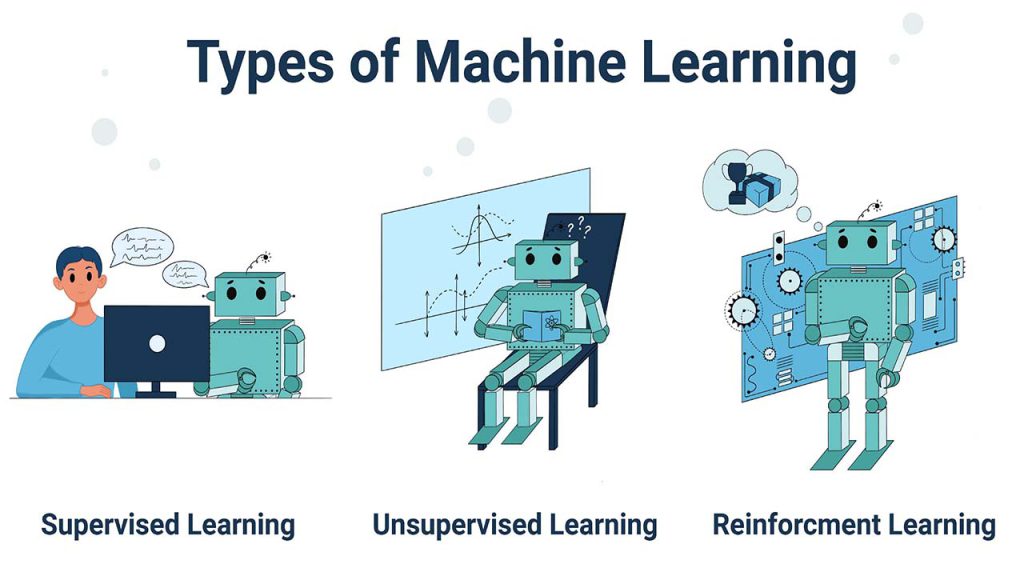
انواع یادگیری ماشین
انتخاب الگوریتم مناسب و یا ترکیب الگوریتمها برای انجام یک کار، چالشی همیشگی برای تمامی فعالین این حوزه میباشد. اما جای نگرانی نیست. با دستهبندی الگوریتمها و دانستن انواع یادگیری ماشین، کار برای شما راحتتر میشود. الگوریتمهای یادگیری ماشین در سه دسته قرار دارند که شامل یادگیری بانظارت (Supervised)، یادگیری بدون نظارت (Unsupervised) و یادگیری تقویتی (Reinforcement) میباشد. در این مقاله انواع یادگیری ماشین و الگوریتم هایش، بررسی می شود.

1- یادگیری با نظارت چیست؟
بهعنوان اولین شاخه از انواع یادگیری ماشین، یادگیری نظارتی بررسی می شود که روی یادگیری الگوها از طریق یافتن رابطههایی بین متغیرها و خروجیها و کار کردن با مجموعه دادههای برچسبدار، تمرکز دارد.
در یادگیری نظارتی، نمونه ورودی با ویژگیهای مختلف به ماشین (که آن را با “X” نمایش میدهند) داده میشود و پیشبینی در قالب خروجی (که آن را با “y” نمایش میدهند) ارائه میشود. چون خروجی و بردارهای ویژگی مشخص است، پس مجموعهداده برچسبدار (Labeled) محسوب میشود. الگوریتم در ادامه، الگوهای موجود در داده را استخراج میکند و یک مدل میسازد که میتواند با داده جدید، همان قوانین نهفته قبلی را بازتولید کند.

مثال یادگیری با نظارت
برای پیشبینی نرخ بازار برای خرید یک ماشین دستدوم، یک الگوریتم نظارتی میتواند با تحلیل روابط بین ویژگیهای ماشین (شامل سال تولید، برند ماشین، مسافت طی شده توسط ماشین و غیره) و قیمت ماشینهای فروخته شده قبلی در طول زمان، مدلی برای پیشبینی قیمت بسازد.
باتوجه به اینکه الگوریتم نظارتی قیمت ماشینهای فروخته شده قبلی در طول زمان را میداند، میتواند برعکس عمل کند تا رابطه بین خصوصیات ماشین و قیمت آن را بیاید. شکل زیر مدل پیشبینی قیمت ماشین را نشان میدهد.

پس از آنکه ماشین قوانین و الگوهای موجود در داده را استخراج کرد، آن چیزی که به عنوان مدل از آن یاد میکنیم را میسازد: یک معادله الگوریتمی برای تولید خروجی برای دادههای جدید بر اساس قوانینی که از دادههای آموزشی استخراج شده است. زمانی که مدل آماده شد، میتواند روی دادههای جدید اعمال شود و میزان دقت محاسبه شود. پس از آنکه مدل هر دو مرحله آموزش و آزمایش را گذراند، آماده است تا در دنیای واقعی مورد استفاده و بهرهبرداری قرار بگیرد.
دوره آموزشی: هنوز انجام پروژه یادگیری ماشین شروع نکردید، چون برنامهنویسی بلد نیستید؟ اصلا نگران نباشید. دوره آموزش پایتون ویژه هوش مصنوعی را در کانال یوتیوب دیتاهاب ببینید.
انواع الگوریتم های یادگیری با نظارت
روشهای یادگیری نظارتی در انواع یادگیری ماشین شامل تحلیل رگرسیون، درخت تصمیم (decision tree)، k نزدیکترین همسایه (k-nearest neighbors)، شبکههای عصبی (neural networks) و ماشینهای بردار پشتیبان (support vector machines) است. هرکدام از این تکنیکها در مقالات مربوطه به طور کاملا معرفی و با مثال بررسی می شوند.
2- یادگیری بدون نظارت چیست؟
نوع دوم از انواع یادگیری ماشین، یادگیری بدون نظارت است. در یادگیری بدون نظارت، همهی متغیرها و الگوهای موجود در داده، دستهبندی نشدهاند. در عوض ماشین باید الگوهای مخفی و برچسبها را از طریق الگوریتمهای یادگیری بدون نظارت بیابد.

الگوریتم خوشهبندی k-means چطور کار می کند؟
الگوریتم خوشهبندی k-means یک مثال معروف از یادگیری بدون نظارت از انواع یادگیری ماشین است. این الگوریتم، نقاط داده (data point) که ظاهراً ویژگیهای مشابه دارند را در یک گروه قرار میدهد. در شکل زیر، مثال خوشهبندی k-means نمایش داده شده است.

اگر نقاط داده را بر اساس رفتار خرید مشتریان شرکتهای کوچک و متوسط (SME: Small and Medium-sized Enterprises) و بزرگ گروهبندی کنید، برای مثال احتمالاً شاهد دو خوشه خواهید بود. چون SMEها و شرکتهای بزرگ معمولاً عادتهای خرید متفاوتی دارند. برای مثال در خرید زیرساختهای ابری (Cloud infrastructure)، ممکن است منابع ساده میزبان ابری و شبکه تحویل محتوا (Content Delivery Network) برای اکثر مشتریان SME گزینه مناسبی باشد.
بااینحال، مشتریان دارای شرکت بزرگ، امکان دارد که یک محصول ابری کاملتر با تمام متعلقات آن که شامل امنیت پیشرفته و محصولات شبکه مثل دیوار امنیتی برنامههای وب (WAF: Web Application Firewall)، یک اتصال شبکه اختصاصی و ابر مجازی خصوصی (VPC:Virtual Private Cloud) است را خریداری کنند. با بررسی رفتارهای خرید مشتریان، یادگیری بدون نظارت قادر خواهد بود که این دو گروه از مشتریان را بدون برچسبهای خاصی که از قبل شرکتها را بهعنوان کوچک، متوسط یا بزرگ دستهبندی کند، تشخیص بدهد.
دوره آموزشی: برای آشنایی بیشتر با انواع یادگیری ماشین و یادگیری انجام پروژه، آموزش یادگیری ماشین به زبان ساده با پایتون را در کانال یوتیوب دیتاهاب ببینید.
مزیت یادگیری بدون نظارت
هر کدام از روشهای انواع یادگیری ماشین مزایایی دارند. نقطه قوت یادگیری بدون نظارت این است که میتوانید الگوهای موجود در داده که شما از وجود آنها اطلاع نداشتید – مثلاً وجود دو دسته بزرگ انواع خریداران – را کشف کنید. تکنیکهای خوشهبندی مثل خوشهبندی k-means پس از شناسایی گروهها، همچنین میتواند بستری برای تحلیل بیشتر، فراهم کند.
در صنعت، از بین انواع یادگیری ماشین روش های یادگیری بدون نظارت به طور خاص، ابزار قدرتمندی در تشخیص تقلب (Fraud detection) هستند- جایی که خطرناکترین حملات معمولاً آنهایی هستند که هنوز دستهبندی (Classified) نشدهاند (شناسایی نشدهاند).
مثال دنیای واقعی یادگیری بدون نظارت: مدل کسبوکار شرکت DataVisor
یک مثال دنیای واقعی یادگیری بدون نظارت شرکت DataVisor است که مدل کسبوکار خود را بر اساس یادگیری بدون نظارت طراحی کرده است. این شرکت که در سال 2013 در کالیفرنیا تأسیس شد، مشتریان خود را از فعالیتهای متقلبانه آنلاین از جمله اسپم، نظرهای تقلبی (Fake reviews)، نصب نرمافزارهای مخرب (Fake app install) و معاملات تقلبی حفاظت میکند. درحالیکه سرویسهای محافظت در برابر تقلب سنتی از مدلهای نظارتی و موتورهای قوانین استفاده میکنند، DataVisor از یادگیری بدون نظارت استفاده میکند که این قابلیت را به آنها میدهد که حملات جدیدی که هنوز طبقهبندینشدهاند را در مراحل اولیه فعالیتشان تشخیص بدهد.

شرکت DataVisor در وبسایت خود توضیح میدهد که «راهحلهای موجود برای تشخیص حملات، به تجربه انسان برای ساختن قوانین یا برچسب زدن دادههای آموزشی، برای بهبود مدل نیازمند است. این مدلها در تشخیص حملات جدیدی که هنوز بهوسیله انسانها شناسایی نشدهاند یا برچسبی درداده آموزشی برایشان نیست، ناتوان هستند.»
در شیوههای سنتی تشخیص حملات، برای یک حمله خاص، رشتهای از فعالیتها تحلیل میشود و سپس برای پیشبینی تکرار حمله، قوانینی طراحی میشود. در چنین سناریویی، متغیر وابسته (Dependent variable) مانند y احتمال رخداد یک حمله و متغیرهای مستقل (Independent variable) مانند X متغیر پیشبینیکننده مشترک (Common predictor variable) از یک حمله هستند.
مثال هایی از حملات سایبری و فعالیتهای تقلبی آنلاین
مثالهایی از متغیرهای مستقل (X) بهصورت زیر است:
- یک سفارش ناگهانی و بزرگ از یک کاربر ناشناس: برای مثال مشتریان شناخته شده معمولاً در هر سفارش خود کمتر از 100 دلار خرج میکنند، ولی یک کاربر جدید 8000 دلار را در یک سفارش، بلافاصله پس از ثبتنام، هزینه میکند.
- یک موج ناگهانی از رتبه دهی (Rating) توسط کاربران: برای مثال به عنوان یک نویسنده معمولی در سایت amazon، پس از انتشار اولین کار، دریافت بیش از یک بازخورد کتاب در فاصله یک الی دو روز رایج نیست. به طور معمول، تقریباً از بین هر 200 خواننده کتاب در آمازون یکی از آنها یک بازخورد برای کتاب مینویسد و اکثر کتابها هفتهها و ماهها بدون بازخورد باقی میمانند. بااینحال، بارها مشاهده شده کتابهایی در طول یک روز 20 الی 50 بازخورد دریافت میکنند! (البته آمازون بازخوردهای مشکوک را چند هفته یا چند ماه بعد حذف میکند.)
- بازخوردهای شبیه یا کاملاً یکسان از کاربران مختلف: در مثال قبلی، گاهی مشاهده میشود که بازخوردهای یک کتاب، چند ماه بعد، برای کتابهای دیگری ثبت میشود (گاهی در بازخورد جدید همچنان اسم نویسنده قبلی وجود دارد!). پس از مدتی آمازون این بازخوردهای تقلبی را حذف میکند و حسابهایی که این بازخوردها را گذاشتهاند به دلیل نقض شرایط و خدمات (Terms and services) معلق (Suspend) میکند.
- آدرس ارسال مشکوک: برای مثال، برای شرکتهای کوچکی که معمولاً محصولات را به مشتریان محلی میرسانند، یک سفارش از یک راه دور (که آن شرکت محصولاتش را در آنجا تبلیغ نمیکند) در برخی شرایط ممکن است نشاندهنده فعالیتهای تقلبی و مخرب باشند.

مثال یادگیری بانظارت برای دسته بندی حملات سایبری
فعالیتهای مستقل مثل سفارش بزرگ ناگهانی یا یک آدرس ارسال دور ممکن است اطلاعات کمی برای پیشبینی فعالیتهای سایبری مجرمانه (Cyber-criminal) سطح بالا باشد و احتمالاً تعداد زیادی مثبت کاذب (False positive) تولید کند. اما یک مدل که ترکیبی از متغیرهای مستقل، مثل یک سفارش خرید بزرگ ناگهانی از شهری دور یا حجم زیادی از بازخوردهای کتاب که از متن بازخوردهای قبلی استفاده میکنند، را زیر نظر میگیرد، عموماً به سمت پیشبینیهای درستتری میرود. اگر از انواع یادگیری ماشین یک مدل نظارتی یادگیری محور انتخاب شود، این مدل میتواند متغیرهای مستقل مشترک (Common independent variable) را بازسازی و دستهبندی کند و یک سیستم برای شناسایی و جلوگیری تکرار جرم طراحی کند.
بااینحال، مجرمان سایبری سطح بالا بهمرور، نحوهی تغییر تکنیکهای خود، برای فرار از موتور قوانین را یاد میگیرند. همچنین مهاجمان قبل از انجام یک حمله، معمولاً یک یا چند حساب کاربری ساخته و رفتارهای کاربران واقعی را تقلید میکنند تا کسی به این حسابها شک نکند. سپس از حسابهای کاربری آماده شده خود، برای فرار از سیستمهای تشخیصی استفاده میکنند. این سیستمها معمولاً تاکید بسیاری روی فعالیتهای کاربران جدید دارند. راهحلهای مبتنی بر یادگیری نظارتی، در شناسایی حملات این عوامل خاموش (Sleeper cell) دچار مشکل میشوند و حملات، صدمات جدی به همراه خواهند داشت البته این قضیه برای حملات جدید و کشف نشده بسیار خطرناکتر است.
مثال یادگیری بدون نظارت و روش k-means برای دسته بندی حملات سایبری
DataVisor و دیگر عرضهکنندههای سیستمهای ضد تقلب (Anti-fraud) از بین انواع یادگیری ماشین از یادگیری بدون نظارت برای رفع محدودیتهای یادگیری نظارتی، به کمک تحلیل الگوها در بین صدها میلیون کاربر و شناسایی رابطههای مشکوک بین آنها – بدون دانستن نوع حملههایی که در آینده اتفاق میافتد – بهره میبرند. با گروهبندی بازیگران مخرب (Malicious actor) و تحلیل کردن ارتباطشان با دیگر حسابهای کاربری، میتوانند از انواع جدیدی از حملات که متغیر مستقل آنها همچنان بدون برچسب و دستهبندی نشده است، جلوگیری کنند.
همچنین عوامل خاموش – در مرحله شبیهسازی و تقلید رفتار کاربران واقعی – از طریق ارتباطشان با حسابهای کاربری مخرب شناسایی میشوند. الگوریتمهای خوشهبندی از جمله خوشهبندی k-means میتوانند چنین گروهبندیهایی را بدون داشتن یک مجموعهداده آموزشی کامل انجام بدهند. منظور از کامل، مجموعه دادهای به فرم متغیرهای مستقلی است که به طور واضحی نشاندهنده حمله هستند (مثل چهار مثالی که قبلتر بیان شد). معمولاً دانش مربوط به متغیر وابسته (حملهکنندههایی که میشناسیم) کلید شناسایی دیگر حملهکنندگان است – قبل از اینکه حمله بعدی اتفاق بیفتد. حسن دیگر استفاده از یادگیری بدون نظارت این است که شرکتهایی مثل DataVisor میتوانند کلیهی اعضا یک دسته از مجرمان را با شناسایی ارتباطات نامحسوس بین کاربران پیدا کنند.
انواع یادگیری بدون نظارت
در این بخش به طور مختصر الگوریتم k-means را معرفی شد. در بخشهای آینده، مبحث یادگیری بدون نظارت بهخصوص تحلیل خوشهبندی بیشتر بررسی خواهد شد. مثالهای دیگر یادگیری بدون نظارت شامل تحلیل رابطه (Association analysis)، تحلیل شبکه اجتماعی (Social network analysis) و الگوریتم کاهش بُعد (Descending dimension) میباشد.
3- یادگیری تقویتی چیست؟
یادگیری تقویتی (Reinforcement Learning) سومین و پیشرفتهترین دسته از انواع یادگیری ماشین است. بر خلاف یادگیری نظارتی و بدون نظارت، یادگیری تقویتی، پیوسته مدل خود را با بهرهگیری از بازخورد (Feedback) تکرارهای (Iteration) قبلی بهبود میدهد. چنین رویکردی با الگوریتمهای قبلی متفاوت است زیرا یادگیریهای نظارتی و بدون نظارت پس از ساخت مدل به کمک دادههای آموزشی و آزمایشی، به یک نقطه انتهایی میرسند و فرایند تمام میشود.
مثال یادگیری تقویتی
از بین انواع یادگیری ماشین، یادگیری تقویتی در ابتدا ممکن است پیچیده به نظر برسد و احتمالاً بهتر است که آن را با بررسی مثالی از یک بازی ویدئویی توضیح بدهیم. هر بازیکن بر اساس میزان پیشرفت خود در بازی، ارزش فعالیتهای مختلف خود را یاد میگیرد و با زمینبازی آشناتر میشود. در حین بازی، این اطلاعات و تجربیات آموخته شده، روی تکتک رفتارهای بازیکن تأثیر گذاشته و آگاهانهتر رفتار میکند. همچنین عملکرد بازیکن بر اساس آموزهها و تجربیات گذشته بهسرعت بهبود مییابد.
یادگیری تقویتی از یک جنبه شباهت زیادی با الگوریتمهای نظارتی و بدون نظارت دارد، آن هم وقتی است که الگوریتمها از طریق یادگیری مداوم، آموزش داده میشوند. یک مدل استاندارد یادگیری تقویتی دارای شاخص ارزیابی عملکرد قابلاندازهگیری است. این شاخص مخصوص زمانی است که خروجیها برچسب خورده نیستند (برچسب صحیح و غلط) – بلکه به خروجیها امتیاز داده میشود. برای مسئله ماشینهای خودران، جلوگیری از تصادف باعث کسب یک امتیاز مثبت و در مثال شطرنج، جلوگیری از شکست یک امتیاز مثبت به همراه دارد

الگوریتم Q-learning در یادگیری تقویتی چیست؟
یک مثال الگوریتمی خاص از یادگیری تقویتی، Q-learning است. در Q-learning، با یک مجموعه از حالتها که با نماد “S” نمایش داده میشود، شروع میکنید. در بازی Pac-Man، حالتها میتوانند چالشها، موانع یا مسیرهای بازی باشند. ممکن است یک دیوار در سمت چپ وجود داشته باشد، یک روح در سمت راست – هرکدام نشاندهندهی یک حالت متفاوت. مجموعه اقدامهای ممکن برای پاسخ به این حالتها را با نماد “A” نشان میدهند. در مثال Pac-Man، اقدامها فقط شامل حرکت به چپ، راست، بالا و پایین و ترکیب آنها میشوند. سومین نماد مهم Q – مقدار شروعکننده – است و دارای مقدار اولیه صفر است.
درحالیکه Pac-Man فضای داخل بازی را جستجو میکند، دو اتفاق مهم میافتد:
- اگر پس از یک حالت/عمل، اتفاقات منفی رخ دهد، مقدار Q کم میشود.
- اگر پس از یک حالت/عمل، اتفاقات مثبت رخ دهد، مقدار Q زیاد میشود.
شکل زیر بازی Pac-Man را نشان میدهد:

در Q-learning، ماشین یاد میگیرد چگونه رفتار کند تا به بیشترین Q ممکن دست پیدا کند یا حداقل Q فعلی را حفظ کند. برای شروع یادگیری، ماشین در یک فرایند شامل حرکات تصادفی (Random movement) (عملها) تحت شرایط مختلفی (حالتها) قرار میگیرد. ماشین نتایج دریافتی (جوایز و جریمهها) و اینکه این حرکات چطور سطح Q را تحتتأثیر قرار میدهند را ذخیره میکند. هدف از ذخیرهسازی، کمک به بهینه و آگاهانهتر شدن رفتار ماشین در آینده است.
با اینکه این روش یادگیری به نظر ساده میرسد، پیادهسازی آن کار بسیار سختی است.
بیشتر بخوانید: بررسی کاملتر یادگیری تقویتی و Q-learning

. . . .
و در انتها…
این مقاله کمی طولانی شد. ولی با یکی از مهمترین مباحث یادگیری ماشین آشنا شدید که در آینده خیلی از آن استفاده خواهید کرد. چون تشخیص الگوریتم مناسب، کار راحتی نیست و آشنایی با انواع یادگیری ماشین به شما کمک زیادی میکند.
انواع یادگیری ماشین در سه دسته قرار داشتند. اول یادگیری بانظارت را گفتیم که تمرکز آن روی مجموعهداده برچسبدار بود. دسته دوم یادگیری بدون نظارت مطرح شد که ماشین باید بتواند الگوهایی را از روی دادههای بدون برچسب پیدا کند. الگوریتم k-means از روشهای مهم این دسته را توضیح دادیم. آخرین دسته، یادگیری تقویتی بررسی شد که پیوسته مدل خود را با استفاده از بازخورد و تکرارهای قبلی بهتر میکند. در نهایت، الگوریتم Q-learning از مهمترین الگوریتمهای یادگیری تقویتی گفته شد.
جزییات الگوریتمهای هر دسته را بعدا میگوییم. اما پیش از آن لازم است داده ها را بشناسیم. در مقاله بعد با دیتاست آشنا می شویم و یاد میگیریم بیگ دیتا چیست.
دوره آموزشی: از بقیه شنیدید برای یادگیری هوش مصنوعی باید ریاضیات بلد باشید و نگرانید که ریاضی را فراموش کردید؟ آموزش سریع جبر خطی را در کانال یوتیوب دیتاهاب ببینید تا خیالتان راحت شود.