
در مقالات اخیر، بررسی الگوریتمهای مختلف یادگیری ماشین را شروع کردیم. گفتیم که رگرسیون چیست و سپس ماشین بردار پشتیبان را بررسی کردیم. در این مقاله خوشه بندی در یادگیری ماشین و روشهای آن را توضیح میدهیم. خوشه بندی یکی از الگوریتمهای یادگیری ماشین است که با توجه به روشهای آن میتواند هم در دستهبندی بانظارت و هم بدوننظارت قرار گیرد. دو روش خوشه بندی در یادگیری ماشین الگوریتم KNN و k-means هستند که در ادامه جزییات هر یک از این روشها را توضیح میدهیم.
. . . .
الگوریتم های خوشه بندی
یکی از شیوههای تحلیل اطلاعات، خوشه بندی (Clustering) دادهها بر اساس ویژگیهای مشترکشان است. برای مثال، شرکتتان بخشی از مشتریان که در زمان مشابه خرید میکنند را بررسی کرده و عوامل مؤثر در رفتار خرید آنها را پیدا میکند.
درک ویژگیهای یک خوشه از مشتریان، در تصمیمگیریها مفید است؛ اینکه از طریق تبلیغات چه محصولاتی را به چه گروهی از مشتریان پیشنهاد بدهید. به جز تحقیقات بازاریابی (Market Research)، خوشه بندی در سناریوهای دیگر، از جمله شناسایی الگو (Pattern Recognition)، تشخیص تقلب (Fraud Detection) و پردازش تصویر (Image Processing) قابلاستفاده است.
تحلیل خوشه بندی در هر دودسته یادگیری بانظارت و یادگیری بدوننظارت قرار میگیرد. بهعنوان یک روش یادگیری بانظارت، از خوشه بندی (به کمک الگوریتم KNN یا همان k نزدیکترین همسایه) برای دستهبندی نقاط داده جدید در خوشههای موجود استفاده میکند و بهعنوان یک روش یادگیری بدوننظارت، خوشه بندی برای شناسایی گروههای گسسته از نقاط داده (به کمک الگوریتم k-means) مورداستفاده قرار میگیرد. با اینکه مدلهای دیگری از تکنیکهای خوشه بندی در یادگیری ماشین وجود دارند، ولی این دو الگوریتم، معروفترینها در هر دو زمینه یادگیری ماشین و دادهکاوی هستند.
 و انواع آن 1")
دوره آموزشی: هنوز انجام پروژه یادگیری ماشین شروع نکردید، چون برنامهنویسی بلد نیستید؟ اصلا نگران نباشید. دوره آموزش پایتون ویژه هوش مصنوعی را در کانال یوتیوب دیتاهاب ببینید.
الگوریتم KNN
سادهترین روش خوشه بندی در یادگیری ماشین، الگوریتم KNN یا k نزدیکترین همسایه (k-NN: k-nearest neighbors) است؛ یک روش یادگیری بانظارت که برای دستهبندی نقاط داده جدید بر اساس نزدیکی با نقاط داده فعلی، استفاده میشود.
الگوریتم KNN شبیه به یک سیستم رأیگیری است. این الگوریتم را شبیه به یک بچه تازهوارد به مدرسه در حال انتخاب یک گروه از همکلاسیها برای داشتن روابط اجتماعی بر اساس پنج همکلاسی که در نزدیکترین محل مینشینند، فرض کنید. در بین این پنج همکلاسی، سه نفر درسخوان (Geek)، یک نفر اسکیتباز و یک نفر ورزشکار است. بر اساس الگوریتم KNN، وقتگذرانی با درسخوانها را به علت مزایای بالای آن انتخاب میکند. بگذارید یک مثال دیگر را بررسی کنیم.
 و انواع آن 2")
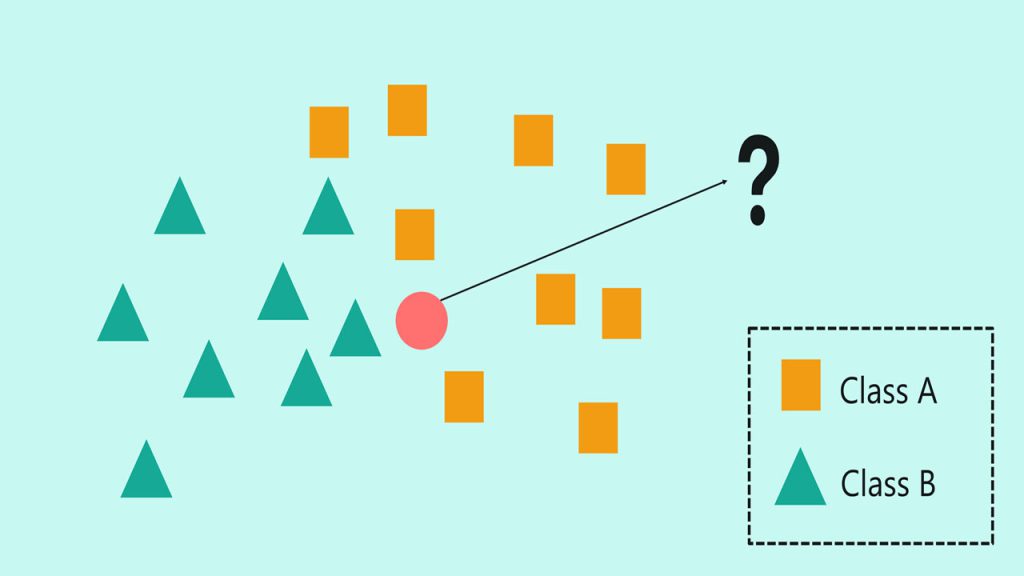
همانطور که در شکل بالا دیده میشود، نمودار پراکندگی، امکان محاسبه فاصله بین هر دو نقطه دادهای را فراهم میکند. قبلاً نقاط داده بر روی نمودار پراکندگی به دو خوشه تقسیم شدهاند. در ادامه، یک نقطه داده جدید که برچسب (Class) آن را نمیدانیم به نمودار اضافه میشود. حال برچسب نقطه داده جدید را بر اساس رابطهاش با نقاط داده موجود، پیشبینی میکنیم.
ولی ابتدا، باید “k” را انتخاب کنیم تا تعداد نقاط داده کاندید برای دستهبندی نقطه داده جدید را مشخص کنیم. اگر مقدار k را 3 قرار بدهیم، الگوریتم KNN تنها رابطه نقطه داده جدید را با سه نقطه داده در نزدیکترین فاصله (همسایهها) را تحلیل میکند. با انتخاب سه تا نزدیکترین همسایه، دو نقطه داده دسته B و یک نقطه داده دسته A را خواهیم داشت. در این شرایط پیشبینی مدل برای نقطه داده جدید دسته B است چون دو همسایه از سه همسایه نزدیک را شامل میشود.
تعداد همسایهها در تشخیص و تعیین نتیجه نهایی، تعریف شده توسط k، نقش مهمی ایفا میکند. در شکل بالا، بسته به اینکه مقدار k، برابر 3 یا 7 باشد، دستهبندی تغییر میکند. پس پیشنهاد میشود که تعداد زیادی از ترکیبات k را مورد آزمایش قرار بدهید تا بهترین k را پیدا کنید. همچنین از مقادیر خیلی کم یا خیلی زیاد برای k اجتناب کنید. انتخاب مقادیر فرد برای k همچنین کمک میکند تا امکان رسیدن به یک بنبست آماری و نتیجه نامعتبر از بین برود. تعداد پیشفرض همسایهها در استفاده از Scikit-learn، پنج است.
با اینکه معمولاً الگوریتم KNN تکنیکی بادقت بالا و ساده است ولی ذخیره کل یک مجموعهداده و محاسبه فاصله بین هر نقطه داده جدید و تمام نقاط داده موجود، بار سنگین محاسباتی دارد. در نتیجه، KNN برای استفاده بر روی مجموعهدادههای بزرگ پیشنهاد نمیشود.
نکته منفی احتمالی دیگر این است که اعمال KNN برای دادههای با بعد بالا (سهبعدی یا چهاربُعدی) با چندین ویژگی میتواند چالشبرانگیز باشد. اندازهگیری چندین فاصله بین نقاط داده در یک فضای سه یا چهاربعدی، فشار مضاعفی بر روی منابع محاسباتی میآورد و همچنین دستهبندی صحیح را پیچیده میکند. کاهش تعداد کل بُعدها، بهوسیله یک الگوریتم کاهش بُعد مثل تحلیل مؤلفههای اصلی (PCA: Principle Component Analysis) یا ادغام متغیرها، یک استراتژی معمول برای سادهسازی و آمادهسازی یک مجموعهداده برای تحلیل الگوریتم KNN است.
دوره آموزشی: برای ورود به دنیای پروژههای یادگیری ماشین، دوره آموزش یادگیری ماشین به زبان ساده با پایتون را در کانال یوتیوب دیتاهاب ببینید.
معرفی روش خوشه بندی K-means
بهعنوان یک الگوریتم معروف یادگیری بدون نظارت، خوشه بندی k-means، دادهها را به k گروه گسسته تقسیم میکند. این الگوریتم در کشف الگوهای ابتدایی دادهها مؤثر است. نمونههایی از گروهبندیهای احتمالی شامل گونههای حیوانات، مشتریان با ویژگیهای مشابه و تقسیمبندی بازار مسکن است. الگوریتم خوشه بندی k-means ابتدا داده را به تعداد k خوشه تقسیم میکند – k نشاندهنده تعداد دلخواه خوشهها است. برای مثال، اگر انتخاب کنید که مجموعهدادهتان را به سه خوشه تقسیم کنید پس مقدار k، برابر 3 میشود. شکل زیر مقایسه داده اصلی و داده خوشه بندی شده با استفاده از الگوریتم k-means را نشان میدهد.
 و انواع آن 3")
در شکل بالا، داده اصلی (خوشه بندی نشده) به سه خوشه تبدیل شده است (مقدار k برابر 3 است). اگر مقدار k را 4 قرار میدادیم، برای ساخت چهار خوشه، یک خوشه اضافه از مجموعهداده جدا میشد.
نحوه کار الگوریتم K-Means
خوشه بندی k-means چگونه نقاط داده را جدا میکند؟ قدم اول بررسی داده خوشه بندی نشده (Unclustered) بر روی نمودار پراکندگی و انتخاب دستی نقاط مرکزی (Centroids) برای هرکدام از خوشهها است که در ادامه این نقاط مرکزی برای هر خوشه یک epicenter ایجاد میکنند. در ابتدا میتوان نقاط مرکزی را تصادفی انتخاب کرد که به آن معنی است که میتوانید هر نقطه دادهای بر روی نمودار پراکندگی را کاندید کنید تا بهعنوان نقطه مرکزی عمل کند. بااینحال، با انتخاب نقاط مرکزی پراکنده در سطح نمودار پراکندگی و نه در نزدیکی یکدیگر میتوانید در زمان صرفهجویی کنید. به بیان دیگر، با حدس اینکه نقطه مرکزی برای هر خوشه کجا میتواند قرار بگیرد، شروع کنید. پس از آن نقاط داده باقیمانده بر روی نمودار پراکندگی به نزدیکترین نقطه مرکزی که توسط فاصله اقلیدسی (Euclidean Distance) محاسبه میشود، تعلق میگیرد. محاسبه فاصله اقلیدسی را در زیر مشاهده میکنید.
دوره آموزشی: از بقیه شنیدید برای یادگیری هوش مصنوعی باید ریاضیات بلد باشید و نگرانید که ریاضی را فراموش کردید؟ آموزش رایگان جبر خطی را در کانال یوتیوب دیتاهاب ببینید تا خیالتان راحت شود.
 و انواع آن 4")
هر نقطه داده تنها میتواند به یک خوشه تعلق بگیرد و خوشهها گسسته خواهند بود پس هیچگونه همپوشانی بین خوشهها وجود ندارد و در هیچ حالتی هیچ خوشهای داخل خوشه دیگر جای نمیگیرد. همچنین، تمام نقاط داده حتی نقاط پرت، بدون توجه به اینکه شکل نهایی خوشه را چطور تحتتأثیر قرار میدهند به یک نقطه مرکزی تعلق میگیرند. بااینحال، به علت نیروی آماری (Statistical Force) که تمام نقاط داده نزدیک به هم را به یک نقطه مرکزی میکشاند، خوشهها معمولاً شکلی بیضوی یا کروی میشوند. مثالی از یک خوشه بیضی در زیر مشاهده میشود.
 و انواع آن 5")
پس از آنکه تمام نقاط داده به یک نقطه مرکزی اختصاص داده شدند، قدم بعدی، جمع تمامی مقادیر نقاط داده برای هر خوشه و میانگینگیری است – محاسبه میانگین مقادیر x و y تمام نقاط داده در هر خوشه.
سپس از مقدار میانگین تمام نقاط داده در خوشه و مقادیر x و y آن، برای بهروزرسانی مختصات نقطه مرکزی استفاده میکنید که بهاحتمال زیاد باعث جابهجایی محل فعلی نقطه مرکزی میشود. بااینوجود، تعداد کل خوشهها، تغییری نخواهد کرد. خوشههای جدیدی نمیسازید، صرفاً محل آنها را بر روی نمودار پراکندگی را بهروزرسانی میکنید. اگر هر نقطه دادهای بر روی نمودار پراکندگی، با تغییر نقاط مرکزی، خوشه خود را تغییر بدهد، قدم قبلی دوباره تکرار میشود. این به معنای محاسبه دوباره متوسط میانگین مقادیر خوشه و بهروزرسانی مقادیر x و y هر نقطه مرکزی است. هدف از این کار اعمال تغییرات میانگین مختصات نقاط داده روی هر خوشه است. زمانی که به مرحلهای برسید که پس از بهروزرسانی مختصات نقطه مرکزی، نقاط داده خوشههای خود را تغییر نمیدهند، الگوریتم کامل میشود و مجموعه نهایی خوشههای خود را خواهید داشت. فرایند الگوریتمی کلی در زیر تشریح شده است.
1- چند نقطه داده بر روی نمودار پراکندگی رسم شدهاند.
 و انواع آن 6")
2- دو نقطه داده بهعنوان نقاط مرکزی کاندید شدهاند.
 و انواع آن 7")
3- پس از محاسبه فاصله اقلیدسی نقاط داده باقیمانده با نقاط مرکزی، دو خوشه تشکیل شده است.
 و انواع آن 8")
4- مختصات نقطه مرکزی برای هر خوشه بهروزرسانی شده تا نشاندهنده مقدار میانگین هر خوشه باشد. ازآنجاییکه یک نقطه داده از خوشه راستی به خوشه چپی تغییر داشته است، نقطه مرکزی هر دو خوشه دوباره محاسبه میشوند.
 و انواع آن 9")
5- بر اساس نقاط مرکزی بهروزرسانی شده برای هر خوشه، دو خوشه نهایی ساخته شدهاند.
 و انواع آن 10")
در خوشه بندی k-means مقدار k چند باشد؟
در تنظیم k، انتخاب تعداد درستی از خوشهها بسیار مهم است. در الگوریتم k-means، معمولاً با افزایش k، خوشهها کوچکتر میشوند و واریانس کاهش مییابد. بااینحال، نکته منفی این است که با افزایش k، میزان تمایز خوشههای همسایه از یکدیگر کمتر میشود.
اگر مقدار k را بهاندازه تعداد نقاط داده در مجموعهداده قرار بدهید، هر نقطه داده به شکل خودکار به یک خوشه مستقل تبدیل میشود. برعکس، اگر مقدار k را 1 قرار بدهید، تمام نقاط داده، همگن تصور میشوند و تنها یک خوشه ساخته میشود. پس مقدارهای خیلی کم یا خیلی زیاد برای k، هیچ بینش تحلیلی باارزشی تولید نمیکند.
بهینهسازی k در خوشه بندی k-means
بهمنظور بهینهسازی k، نمودار scree (شکل زیر) کمککننده است. نمودار scree درجه پراکندگی (واریانس) در داخل یک خوشه را با افزایش تعداد کل خوشهها نشان میدهد. یک مفهوم معروف در نمودارهای scree، “بازو (Elbow)” است که نشانگر پیچهای موجود در منحنی نمودار میباشد.
 و انواع آن 11")
نمودار scree مجموع مربع خطا (SSE: Sum of squared error) برای ترکیبهای مختلف از خوشهها را مقایسه میکند. SSE به شکل مجموع مربع فاصله بین نقطه مرکزی و دیگر همسایگان داخل یک خوشه محاسبه میشود. نکته کلیدی این است که با افزایش تعداد خوشهها، مقدار SEE کاهش مییابد.
تعداد بهینه خوشهها در الگوریتم k-means
حالا یک سؤال مهم مطرح میشود که تعداد بهینه خوشهها چیست؟ برای پاسخ به این سؤال بهتر است به سراغ نمودار رفته و به دنبال جایی در سمت چپ باشید که SSE به طور چشمگیری کاهش پیدا کرده باشد، اما از سمت راست، شاهد تغییرات ناچیز باشیم به صورتی که تقریباً منحنی به حالت ثابت رسیده باشد. برای مثال در شکل 10، مقدار SSE برای شش خوشه یا بیشتر، تغییرات اندکی میکند که باعث ساخت خوشههای کوچکی میشود که تمایز بین آنها دشوار میشود.
در این نمودار scree، دو یا سه خوشه به نظر گزینه ایدهآلی است. در سمت چپ وقتی تعداد خوشهها 2 باشد شاهد جهشی (Kink) بزرگ هستیم که میتواند یک نقطه مناسب برای drop-off باشد. در این حالت و با حرکت به سمت راست همچنان تغییرات کوچکی در مقدار SSE مشاهده میشود. این باعث اطمینان میشود که این دو خوشه متمایز هستند و بر روی دستهبندی داده تأثیر دارند.
مثال انتخاب مقدار k در روش خوشه بندی k-means
یک شیوه سادهتر و کمتر ریاضیاتی برای انتخاب مقدار k استفاده از دانش دامنه است. برای مثال، اگر دادههای بازدیدکنندگان وبسایت یک ارائهدهنده خدمات فناوری اطلاعات را تحلیل کنم، ممکن است مقدار k را 2 قرار بدهم. چرا دو خوشه؟ زیرا از قبل میدانم که احتمالاً اختلاف زیادی بین بازدیدکنندههای قدیمی و جدید وجود دارد – از لحاظ رفتاری و خصوصاً انجام تراکنشها. خیلی بعید است که بازدیدکنندههای جدید، محصولات و خدمات فناوری اطلاعات در سطح سازمانی خریداری کنند، چون قبل از خرید معمولاً یک بازه طولانی تحقیقات و فرایند ارزیابی را میگذرانند.
در نتیجه، میتوانم از خوشه بندی k-means برای ساختن دو خوشه و آزمودن فرضیه خود استفاده کنم. پس از ساختن دو خوشه، ممکن است بخواهم یکی از دو خوشه را، یا با استفاده از تکنیک دیگری و یا دوباره با استفاده از خوشه بندی k-means بیشتر بررسی کنم. برای مثال، ممکن است بخواهم بازدیدکنندههایی که دوباره برمیگردند را به دو خوشه (با استفاده از خوشه بندی k-means) تقسیم کنم تا فرضیه خود درباره اینکه کاربران موبایل و کاربران کامپیوتر میزی (Desktop Users) دو گروه مجزا را تشکیل میدهند، بررسی کنم. دوباره از دانش دامنه استفاده میکنم که معمولاً سازمانهای بزرگ خریدهای مهم خود را با موبایل انجام نمیدهند. برای بررسی این فرض، یک مدل یادگیری ماشین میسازم.
بااینحال، اگر صفحه یک محصول ارزان را تحلیل کنم، برای مثال یک دامنه 4.99 دلاری، بازدیدکنندگان جدید و قدیمی ممکن است دو خوشه متمایز و دقیق نسازند. چون کاربران جدید قبل از خرید دامنه، به علت ارزانی محصول، نیازمند تحلیل و بررسی خاصی نخواهند بود.
در عوض، ممکن است بر اساس سه دسته اولیه بازدیدکنندهها، مقدار k را 3 قرار بدهم: ترافیک ارگانیک (Organic Traffic) (بازدیدکنندههایی که از طریق جستجو و بدون لینکهای تبلیغاتی که برای آنها پول پرداخت شده باشد، وارد سایت شدهاند)، ترافیک پرداخت شده(Paid Traffic) (بازدیدکنندههایی که از لینکهای تبلیغاتی وارد شدهاند) و بازاریابی ایمیلی (Email Marketing).
الف) ترافیک ارگانیک: معمولاً شامل هر دودسته مشتریان جدید و مشتریان قبلی میشوند که با نیت خرید قطعی از وبسایت آمدهاند (از قبل تصمیم به خرید گرفتهاند از طریق آشنایی دهانبهدهان، تجربه قبلی مشتری).
ب) ترافیک پرداخت شده: خریداران جدیدی که معمولاً با سطح پایینتری از اعتماد نسبت به ترافیک ارگانیک وارد وبسایت میشوند را هدف قرار میدهد، از جمله مشتریان احتمالی که بهاشتباه بر روی تبلیغات پولی کلیک میکنند.
ج) بازاریابی ایمیلی: مشتریان موجودی که قبلاً تجربه خرید از وبسایت را داشتهاند و حساب کاربری ساختهاند را هدف قرار میدهد.
این یک مثال از کاربرد دانش دامنه (Domain Knowledge) بر اساس شغل خودم است، ولی باید در نظر گرفت که با افزایش تعداد خوشهها تأثیر”دانش دامنه” کاهش مییابد. به بیان دیگر، دانش دامنه ممکن است برای تشخیص دو یا چهار خوشه کافی باشد ولی در انتخاب بین 20 یا 21 خوشه کارایی چندانی نخواهد داشت.
. . . .
و در انتها…
در این بخش، روش های خوشه بندی یعنی الگوریتم k-means و KNN را کامل توضیح دادیم. در مقاله بعد موقتا الگوریتمها را کنار گذاشته و درباره تفاوت بایاس و واریانس صحبت می کنیم. پس از آن، الگوریتمهای یادگیری ماشین را ادامه میدهیم.