
در مقاله درخت تصمیم چیست دیدیم که ماشین ها هم می توانند بر سر دوراهی قرار گیرند. در ادامه و به عنوان آخرین الگوریتم یادگیری ماشین که در این سری از مقالات معرفی میکنیم، به سراغ مدلسازی جمعی میرویم. یکی از مؤثرترین شیوههای یادگیری ماشین، مدلسازی جمعی است که بهعنوان “گروهها (Ensembles)” نیز شناخته میشود. مدلسازی جمعی، برای ساخت مدل پیشبینیکننده یکپارچه، تکنیکهای آماری را ترکیب میکند.
. . . .
یادگیری جمعی (Ensemble learning) چیست؟
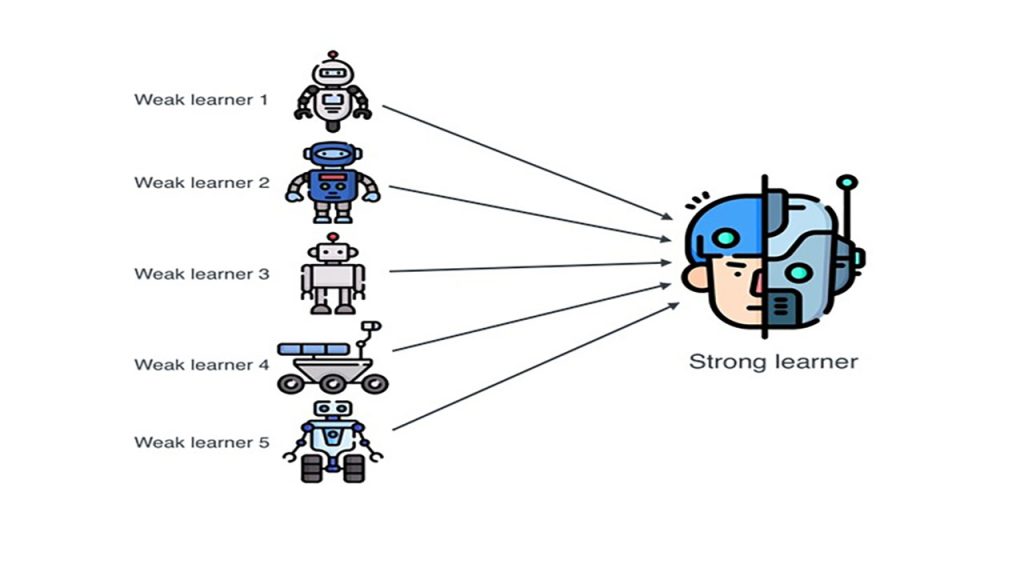
یادگیری جمعی یا گروهی، با ترکیب پیشبینیها و دنبالکردن دانش گروه است که یک دستهبندی نهایی یا خروجی با پیشبینی بهتر را ارائه میدهد. طبیعتاً، روش های یادگیری جمعی انتخاب محبوبی در رقابتهای یادگیری ماشین مثل مسابقات نتفلیکس (Netflix Competition) و kaggle هستند.
روش های یادگیری جمعی را میتوان به دستههای مختلفی دستهبندی کرد از جمله ترتیبی (Sequential)، موازی (Parallel)، همگن (Homogenous) و ناهمگن (Heterogeneous). ابتدا به سراغ مدلهای ترتیبی و موازی میرویم. برای مدلهای جمعی ترتیبی، خطای پیشبینی از طریق اضافهکردن وزن به دستهبندیهایی که قبلاً داده را به اشتباه دستهبندی کردهاند، کاهش مییابد. Gradient boosting و AdaBoost دو مثال از مدلهای ترتیبی هستند. برعکس، مدلهای جمعی موازی، هم زمان کار میکنند و با میانگینگیری خطا را کاهش میدهند. درختهای تصمیم مثالی از این تکنیک هستند.
روش های یادگیری جمعی همچنین میتوانند با استفاده از یک تکنیک با تغییرات زیاد (که بهعنوان گروه همگن شناخته میشود) یا از طریق تکنیکهای مختلف (که بهعنوان گروه ناهمگن شناخته میشوند) ساخته شوند. یک مثال از مدل گروه همگن، تعداد زیادی درخت تصمیم (bagging) است. یک مثال از گروه ناهمگن استفاده از خوشهبندی k-means یا یک شبکه عصبی در همکاری با یک مدل درخت تصمیم است. طبیعتاً، تکنیکها باید به نحوی انتخاب بشوند که یکدیگر را تکمیل کنند. برای مثال، شبکههای عصبی، برای تحلیل به دادههای کامل نیاز دارند، درحالیکه درختهای تصمیم به طور مؤثری دادههای ناموجود را مدیریت میکنند. این دو تکنیک، در کنار هم و نسبت به مدل همگن، ارزش افزوده خواهند داشت. شبکه عصبی بخش اعظمی از نمونهها را بهدرستی پیشبینی خواهد کرد و درخت تصمیم از اینکه هیچ نتیجهای “null” نباشد، اطمینان حاصل خواهد کرد – چون شبکه عصبی برای دادههای ناموجود، خروجی ندارد و درخت تصمیم این مشکل را پوشش میدهد. نکته مثبت دیگر مدلسازی جمعی این است که چند پیشبینی معمولاً صحیحتر از تک پیشبینی خواهد بود.
دوره آموزشی: برای یادگیری برنامه نویسی الگوریتمهای یادگیری ماشین، دوره آموزش یادگیری ماشین به زبان ساده با پایتون را رایگان در کانال یوتیوب دیتاهاب ببینید.
انواع روش های یادگیری جمعی
زیرگروههای دیگری از روش های یادگیری جمعی وجود دارد که تاکنون دو نوع از آن را بررسی کردیم. چهار زیرگروه معروف یادگیری جمعی Bagging، Boosting، Bucket of models و Stacking هستند.
Bagging چیست؟
Bagging، همانطور که میدانیم، مخفف “boosted aggregating” است و مثالی از گروه همگن است. این روش با استفاده از مجموعهدادههایی که بهتصادف استخراج شدهاند و ترکیب پیشبینی آنها، برای ساخت یک مدل یکپارچه بر اساس فرایند رأیگیری عمل میکند. به بیان دیگر، bagging یک روش خاص از میانگینگیری مدل است. جنگل تصادفی یک مثال معروف از bagging است.
Boosting چیست؟
Boosting تکنیک معروف جایگزینی است که در ساخت مدل نهایی، خطا و دادههایی که در تکرارهای قبلی اشتباهاً دستهبندی شدهاند را مدنظر قرار میدهد. Gradient boosting و AdaBoost هر دو مثالهای معروفی از boosting هستند.
 و بررسی انواع آن 1")
آشنایی با Bucket of models
Bucket of models، تعداد زیادی از مدلهای الگوریتمی مختلف را با استفاده از یک داده آموزشی، آموزش میدهد و سپس مدلی که بیشترین دقت را بر روی داده آزمایشی دارد انتخاب میکند.
معرفی روش Stacking
Stacking، همزمان چند مدل را بر روی داده اجرا میکند و برای ساخت مدل نهایی، نتایج را ترکیب میکند. در حال حاضر، این روش، در رقابتهای یادگیری ماشین محبوب است، از جمله Netflix Prize.
با اینکه روش های یادگیری جمعی معمولاً پیشبینیهای صحیحتری انجام میدهند اما پیچیدگی بالایی دارند. گروهها همان مصالحه و مشکل حد وسط بین دقت و سادگی موجود بین یک درخت تصمیم و یک جنگل تصادفی، را دارند. شفافیت و سادگی تکنیک سادهای مثل درخت تصمیم یا k نزدیکترین همسایه، از بین رفته و به یک جعبه سیاه آماری جهشیافته است. در اکثر مواقع، مدل عملکردی خوبی نشان میدهد ولی شفافیت مدل فاکتور دیگری است که در زمان انتخاب مدل باید مدنظر قرار گرفته شود. و بررسی انواع آن 2")
. . . .
در مقالات اخیر الگوریتمهای مختلف یادگیری ماشین را بررسی کردیم. ابتدا روشهای تحلیل رگرسیون شامل رگرسیون خطی و رگرسیون منطقی را توضیح دادیم. سپس SVM را معرفی کردیم که نوع پیشرفتهای از رگرسیون بود. با روشهای خوشهبندی KNN و k-means آشنا شدیم. شبکههای عصبی، یک تکنیک شناختهشده یادگیری ماشین برای پردازش داده از طریق لایههای تحلیلی بود که به مغز انسان شباهت داشت. در ادامه، شبکه عصبی پرسپترون و یادگیری عمیق مطرح شدند. درخت تصمیم از الگوریتمهای ساده یادگیری ماشین بود که تفسیر سادهای داشت. در آخر نیز با مدلسازی گروهی و زیرگروههای آن آشنا شدیم.
بررسی الگوریتمهای یادگیری ماشین در اینجا به پایان میرسد. با شناخت الگوریتمهای مختلف، میتوانیم مدل یادگیری ماشین واقعی بسازیم. اما ابتدا باید زبان برنامه نویسی مناسبی را انتخاب کنیم. بنابراین در قسمت بعدی درباره زبان های برنامه نویسی یادگیری ماشین مختلف و کاربرد آن ها صحبت می کنیم.
دوره آموزشی: هنوز انجام پروژه یادگیری ماشین شروع نکردید، چون برنامهنویسی بلد نیستید؟ اصلا نگران نباشید. دوره آموزش پایتون ویژه هوش مصنوعی را در کانال یوتیوب دیتاهاب ببینید.